

真正的王炸组合!微信终于接入满血版DeepSeek R1,灰度测试中
真正的王炸组合!微信终于接入满血版DeepSeek R1,灰度测试中一觉醒来,AI应用的天变了!而且据腾讯回应消息,接入的还是满血版 DeepSeek R1!微信正在灰度测试该模型,部分灰度到的用户可以内测相关的 AI 搜索功能。
来自主题: AI资讯
9623 点击 2025-02-16 11:22
一觉醒来,AI应用的天变了!而且据腾讯回应消息,接入的还是满血版 DeepSeek R1!微信正在灰度测试该模型,部分灰度到的用户可以内测相关的 AI 搜索功能。
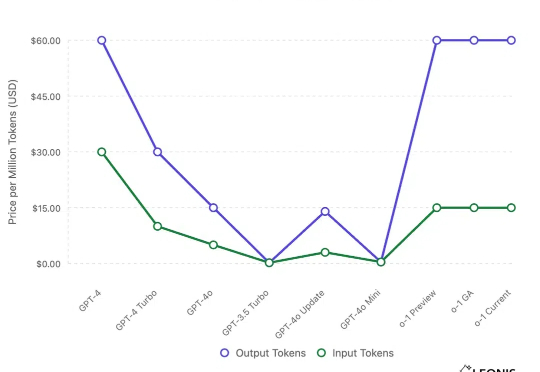
自一月以来, DeepSeek 在 AI 领域引发了极大的热度,也出现了大量分析文章。其中来自 Leonis Capital 于 2.6 发表于 Substack 上的文章:「DeepSeek: A Technical and Strategic Analysis for VCs and Startups」

这项尝试只用到了 R1 模型和基本验证器,没有针对 R1 的工具,没有对专有的英伟达代码进行微调。其实根据 DeepSeek 介绍,R1 的编码能力不算顶尖。
整个春节假期,我眼睁睁看着 DeepSeek 从“全民狂欢”变成“全民卡顿”——官网十问九崩,还有谁没被“服务器正忙,请稍后重试”的提示,搞崩溃过。

席卷全球的 DeepSeek 依然是科技圈最大的话题,连 San Altman 都承认每天醒来都会担忧。因此本周在巴黎举办的 AI 行动峰会聚光灯稍显黯淡,但这里依然汇聚了全球大量重要的头脑。

DeepSeek 最近的爆火程度令人咋舌。短短20天内用户量就突破3000万,导致官方服务器几乎天天处于过载状态。虽然市面上已经涌现出不少第三方接入平台,但这些平台大多针对个人用户,对开发者和企业的需求难以满足。

还在为 DeepSeek R1 官网的卡顿抓狂?无问芯穹大模型服务平台现已上线满血版 DeepSeek-R1、V3,无需邀请即可免费用 Token!另有异构算力鼎力相助,支持通过 Infini-AI 异构云平台一键获取 DeepSeek 系列模型与多元异构自主算力服务。

DeepSeek 在海内外搅起的惊涛巨浪,余波仍在汹涌。当中国大模型撕开硅谷的防线之后,在预设中总是落后半拍的中国 AI 军团,这次竟完成了一次反向技术输出,引发了全球范围内复现 DeepSeek 的热潮。
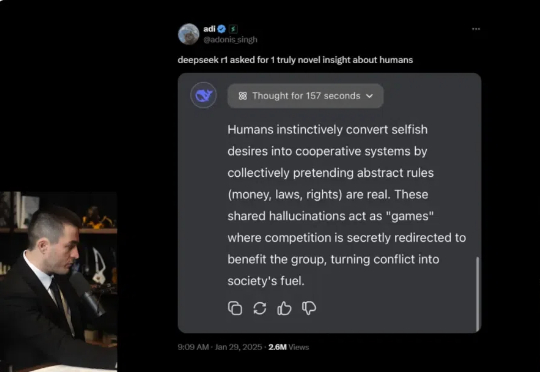
DeepSeek火了之后,知名科技主播Lex Fridman,找了两位嘉宾,从 DeepSeek 及其开源模型 V3 和 R1 谈到了 AI 发展的地缘政治竞争,特别是中美在 AI 芯⽚与技术出⼝管制上的博弈。5 个小时的对谈,基于「赛博禅心」的翻译版本,我们精选出了5 万字,基本把 DeepSeek 的创新、目前 AI 的算力问题、AI 训练和蒸馏、以及产品落地等都聊透了。建议收藏后仔细阅读。

新年伊始,在估值攀上 3400 亿美元的新巅峰后,OpenAI 也辞旧迎新,更换了新字体、新标志、新配色方案,进行了一次全面的品牌重塑。Open AI 这次重塑的目的,一是为了摆脱设计总监 Shannon Jager 所说的「OpenAI 一直在用相当随意的方式,向世界展示自己。字体、Logo 和颜色的杂乱无章,只会彰显出公司缺乏明确的统一战略。」